

Today’s robots are often static and isolated from humans in structured environments — you can think of robot arms employed by Amazon for picking and packaging products within warehouses. But the true potential of robotics lies in mobile robots operating alongside humans in messy environments like our homes and hospitals — this requires navigation skills.
Imagine dropping a robot in a completely unseen home and asking it to find an object, let’s say a toilet. Humans can do this effortlessly: when looking for a glass of water at a friend’s house we’re visiting for the first time, we can easily find the kitchen without going to bedrooms or storage closets. But teaching this kind of spatial common sense to robots is challenging.
Many learning-based visual navigation policies have been proposed to tackle this problem. But learned visual navigation policies have predominantly been evaluated in simulation. How well do different classes of methods work on a robot?
We present a large-scale empirical study of semantic visual navigation methods comparing representative methods from classical, modular, and end-to-end learning approaches across six homes with no prior experience, maps, or instrumentation. We find that modular learning works well in the real world, attaining a 90% success rate. In contrast, end-to-end learning does not, dropping from 77% simulation to 23% real-world success rate due to a large image domain gap between simulation and reality.
Object goal navigation
We instantiate semantic navigation with the Object Goal navigation task, where a robot starts in a completely unseen environment and is asked to find an instance of an object category, let’s say a toilet. The robot has access to only a first-person RGB and depth camera and a pose sensor.

This task is challenging. It requires not only spatial scene understanding of distinguishing free space and obstacles and semantic scene understanding of detecting objects, but also requires learning semantic exploration priors. For example, if a human wants to find a toilet in this scene, most of us would choose the hallway because it is most likely to lead to a toilet. Teaching this kind of common sense or semantic priors to an autonomous agent is challenging. While exploring the scene for the desired object, the robot also needs to remember explored and unexplored areas.

Methods
So how do we train autonomous agents capable of efficient navigation while tackling all these challenges? A classical approach to this problem builds a geometric map using depth sensors, explores the environment with a heuristic, like frontier exploration, which explores the closest unexplored region, and uses an analytical planner to reach exploration goals and the goal object as soon as it is in sight. An end-to-end learning approach predicts actions directly from raw observations with a deep neural network consisting of visual encoders for image frames followed by a recurrent layer for memory. A modular learning approach builds a semantic map by projecting predicted semantic segmentation using depth, predicts an exploration goal with a goal-oriented semantic policy as a function of the semantic map and the goal object, and reaches it with a planner.
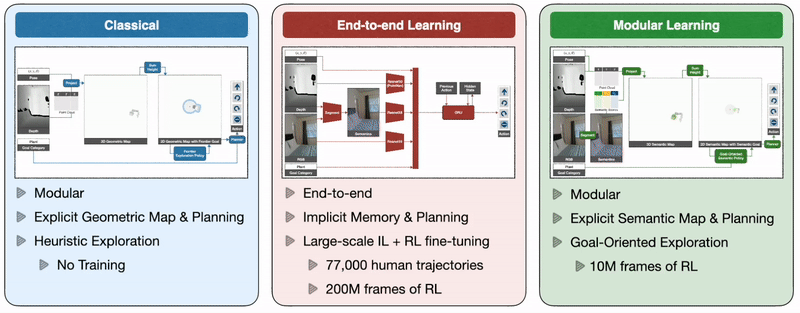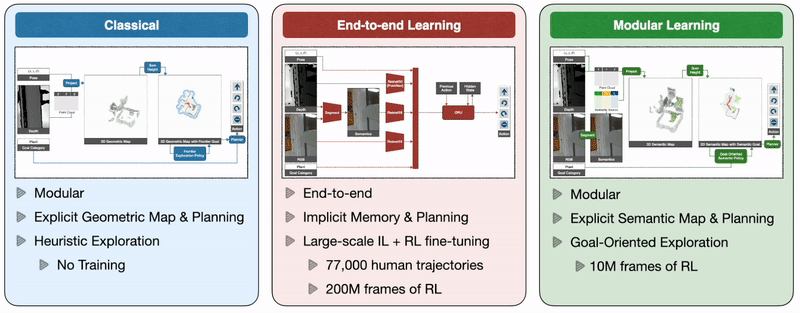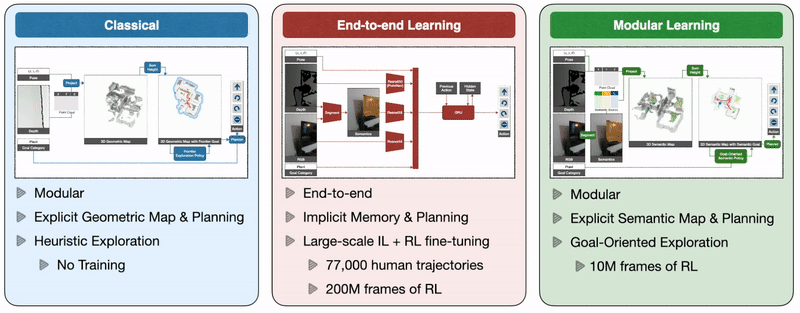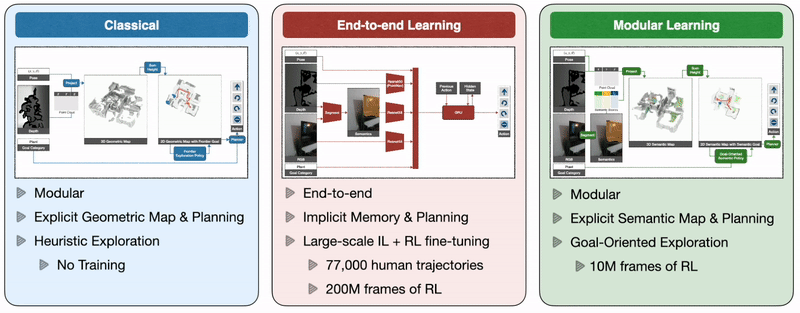
Large-scale real-world empirical evaluation
While many approaches to navigate to objects have been proposed over the past few years, learned navigation policies have predominantly been evaluated in simulation, which opens the field to the risk of sim-only research that does not generalize to the real world. We address this issue through a large-scale empirical evaluation of representative classical, end-to-end learning, and modular learning approaches across 6 unseen homes and 6 goal object categories.

Results
We compare approaches in terms of success rate within a limited budget of 200 robot actions and Success weighted by Path Length (SPL), a measure of path efficiency. In simulation, all approaches perform comparably, at around 80% success rate. But in the real world, modular learning and classical approaches transfer really well, up from 81% to 90% and 78% to 80% success rates, respectively. While end-to-end learning fails to transfer, down from 77% to 23% success rate.

We illustrate these results qualitatively with one representative trajectory. All approaches start in a bedroom and are tasked with finding a couch. On the left, modular learning first successfully reaches the couch goal. In the middle, end-to-end learning fails after colliding too many times. On the right, the classical policy finally reaches the couch goal after a detour through the kitchen.

Result 1: modular learning is reliable
We find that modular learning is very reliable on a robot, with a 90% success rate. Here, we can see it finds a plant in a first home efficiently, a chair in a second home, and a toilet in a third.

Result 2: modular learning explores more efficiently than classical
Modular learning improves by 10% real-world success rate over the classical approach. On the left, the goal-oriented semantic exploration policy directly heads towards the bedroom and finds the bed in 98 steps with an SPL of 0.90. On the right, because frontier exploration is agnostic to the bed goal, the policy makes detours through the kitchen and the entrance hallway before finally reaching the bed in 152 steps with an SPL of 0.52. With a limited time budget, inefficient exploration can lead to failure.
Result 3: end-to-end learning fails to transfer
While classical and modular learning approaches work well on a robot, end-to-end learning does not, at only 23% success rate. The policy collides often, revisits the same places, and even fails to stop in front of goal objects when they are in sight.
Analysis
Insight 1: why does modular transfer while end-to-end does not?
Why does modular learning transfer so well while end-to-end learning does not? To answer this question, we reconstructed one real-world home in simulation and conducted experiments with identical episodes in sim and reality.
The semantic exploration policy of the modular learning approach takes a semantic map as input, while the end-to-end policy directly operates on the RGB-D frames. The semantic map space is invariant between sim and reality, while the image space exhibits a large domain gap. In this example, this gap leads to a segmentation model trained on real-world images to predict a bed false positive in the kitchen.
The semantic map domain invariance allows the modular learning approach to transfer well from sim to reality. In contrast, the image domain gap causes a large drop in performance when transferring a segmentation model trained in the real world to simulation and vice versa. If semantic segmentation transfers poorly from sim to reality, it is reasonable to expect an end-to-end semantic navigation policy trained on sim images to transfer poorly to real-world images.
Insight 2: sim vs real gap in error modes for modular learning
Surprisingly, modular learning works even better in reality than simulation. Detailed analysis reveals that a lot of the failures of the modular learning policy that occur in sim are due to reconstruction errors, which do not happen in reality. Visual reconstruction errors represent 10% out of the total 19% episode failures, and physical reconstruction errors another 5%. In contrast, failures in the real world are predominantly due to depth sensor errors, while most semantic navigation benchmarks in simulation assume perfect depth sensing. Besides explaining the performance gap between sim and reality for modular learning, this gap in error modes is concerning because it limits the usefulness of simulation to diagnose bottlenecks and further improve policies. We show representative examples of each error mode and propose concrete steps forward to close this gap in the paper.
Takeaways
For practitioners:
- Modular learning can reliably navigate to objects with 90% success.
For researchers:
- Models relying on RGB images are hard to transfer from sim to real => leverage modularity and abstraction in policies.
- Disconnect between sim and real error modes => evaluate semantic navigation on real robots.
For more content about robotics and machine learning, check out my blog.

Theophile Gervet
is a PhD student at the Machine Learning Department at Carnegie Mellon University
Theophile Gervet
is a PhD student at the Machine Learning Department at Carnegie Mellon University